Table of Contents
The gut feeling was never the enemy. The illusion that you have moved past the need for judgment is.
For 25 years, everyone who worked in SEO knew — explicitly or intuitively — that keyword research was an approximation. You were using word-matching as a proxy for meaning-matching, and the gap between those two things was large enough to see with the naked eye.
Keyword tools couldn’t tell you if a page was actually about what a user was searching for. They could only tell you whether the right words appeared on the page. The limitation was so obvious that it kept practitioners honest. You knew you were guessing.
You guessed better over time. You built supporting content and triangulated intent from multiple angles precisely because you understood that no single keyword signal could settle the question.
Then came vector-based semantic analysis. Embedding models that represent both content and queries as mathematical vectors in high-dimensional space, measuring the angular distance between them as a proxy for semantic similarity. Cosine similarity scores. Alignment metrics. Numbers with decimal places.
And something subtle but consequential shifted. Not the technology — the technology genuinely is better. The shift was psychological. A number with decimal places feels like a measurement. A measurement feels like a fact. A fact feels like a decision made.
That shift from “I’m approximating” to “I’m measuring” is exactly where the danger lives.
A 60-Year-Old Idea That Got Dramatically More Powerful (But Not Perfect)
The vector space model for document retrieval isn’t new technology dressed up in modern clothes. Gerard Salton introduced it at Cornell in the 1960s as part of the SMART system — one of the foundational frameworks in information retrieval.
The core idea, represent both the document and the query as vectors in a shared space, measure the angle between them, and use that angle as a proxy for relevance.
What’s changed across 60 years of development isn’t the conceptual framework. It’s the sophistication of how those vectors are constructed. Salton used term frequency.
Modern embedding models use transformer-derived representations — trained on vast corpora of text, encoding semantic relationships, contextual meaning, and conceptual proximity across hundreds or thousands of dimensions.
The gap between term-frequency vectors and transformer embeddings is enormous. The instrument got dramatically better.
But the thing being measured — the angular distance between two vector representations as a proxy for a real-world relevance relationship — is still a proxy. The math improved. The fundamental nature of what the math is doing did not.
This distinction matters more than it might seem. When the proxy was crude, practitioners knew it was crude. When the proxy becomes sophisticated enough to feel precise, the temptation is to stop thinking of it as a proxy at all.
What the Research Actually Shows About Cosine Similarity
In 2024, researchers from Netflix — Steck, Ekanadham, and Kallus — published a study examining cosine similarity as applied to learned embedding models. Their conclusion was striking: cosine similarity in embedding spaces can produce results that are, in their framing, “arbitrary.” Not inaccurate in a predictable direction. Arbitrary.
The reason is architectural. The geometry of an embedding space — the relative distances and angles between vectors — is shaped by how the model was trained.
The regularization applied. The data it saw. The optimization objective it was trained toward. Two embedding models trained on similar data with different architectures will produce meaningfully different geometries.
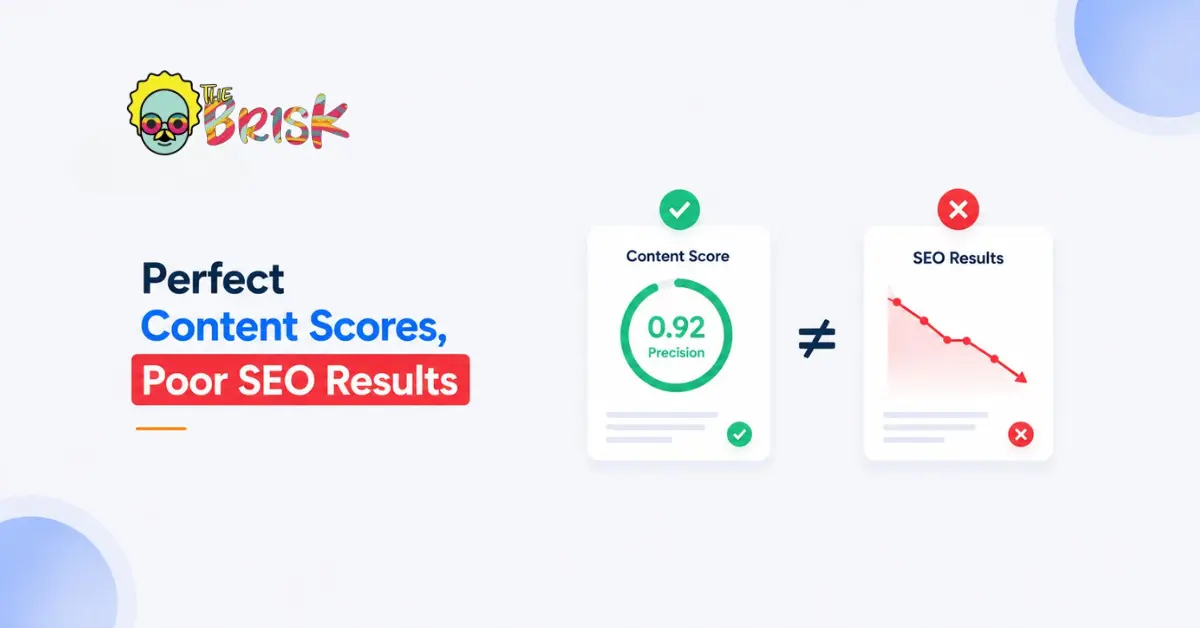
A cosine similarity score of 0.85 in one model’s space has no guaranteed equivalence to a score of 0.85 in a different model’s space. The score is real within its geometry. Whether that geometry represents the relationship you care about is a separate question.
For content practitioners, the implication is direct and uncomfortably concrete. When you score your content’s alignment to a query using a scoring tool, you’re measuring semantic proximity inside that specific tool’s embedding model.
You are not measuring how Google’s retrieval infrastructure evaluates the relationship. You’re not measuring how OpenAI’s RAG pipeline processes it. You’re not measuring how Perplexity’s index treats it.
Those systems use their own embedding models, their own retrieval architectures, and their own reranking layers.
There is no public registry of which model powers which production system’s retrieval layer. You are measuring in a representative space — one that captures something real about semantic language — but not the specific space where your content will actually be evaluated.
A score of 0.92 in your measurement space might correspond to strong retrieval in one system, weak retrieval in another, and irrelevance in a third. The number is real. What it represents may not transfer.
Why Decimal Places Are Dangerous
Here’s the cognitive trap, stated plainly: humans treat precise numbers differently than imprecise ones.
Tell someone their content “seems to be roughly on-topic” and they’ll keep questioning it, refining it, seeking additional signals. Tell someone their content has an alignment score of 0.87 and they will often treat the question as answered. The number feels like a verdict.
This is Goodhart’s Law operating in the wild. The observation — originally made in the context of economic policy — is that when a measure becomes a target, it ceases to be a good measure.
Once an alignment score becomes the goal rather than a signal, content starts drifting toward the score’s geometry rather than toward genuine relevance.
You start optimizing for the embedding model you’re measuring against. That model is not the one any production system uses. The content gets tuned for a proxy of a proxy.
The old instrument’s bluntness was, in a real sense, a feature. It made the proxy nature of the measurement impossible to ignore. When you could see the gap clearly, you used judgment to bridge it. When the instrument is precise enough to obscure the gap, judgment quietly stops being applied.
Keyword Research vs. Vector Alignment
This is not an argument that keyword research is sufficient. It isn’t. The environments where content competes in 2025 — AI overviews, RAG-based retrieval, LLM-generated answers — operate in semantic space, not lexical space.
A page can achieve perfect keyword coverage while being semantically adrift from the actual user intent the query represents. Conversely, a page can use none of the target keywords and still be strongly aligned conceptually.
The paraphrase and synonym space that language models operate in is structurally invisible to keyword-based evaluation.
A practical illustration: imagine keyword research correctly identifies “customer churn prevention strategies” as a high-value content target. The content team builds a thorough piece that covers the topic, uses target terms naturally, and would pass any keyword audit without issue.
Then an alignment score reveals something keyword tools couldn’t see — the content’s semantic center of gravity sits closer to “measuring churn” than to “preventing churn.”
The piece leans heavily on diagnostic framing: how to identify at-risk accounts, how to calculate churn rates, how to segment by behavior. The intervention layer — what to actually do once you’ve identified the problem — is thin.
Both treatments satisfy the keyword target. Both are topically relevant. But the semantic distance between the content and what a retrieval system understands the query to represent is larger than keyword coverage suggests. Keyword research has no instrument to surface that drift. Vector alignment does. This is a genuine and material capability upgrade.
The problem isn’t choosing between them. It’s practitioners who decide that because keyword research is no longer sufficient, vector alignment is the complete replacement. That’s trading one approximation for a better one while losing the awareness that it remains an approximation.
What Keyword Research Can See:
- Explicit lexical overlap between content and query
- Presence or absence of target terms and phrases
- Basic topical coverage at the word level
- Competitor keyword gaps
What Keyword Research Cannot See:
- Semantic drift between content framing and query intent
- Conceptual coverage that uses different vocabulary
- Whether the content addresses the query’s actual informational need
- How LLM-based retrieval systems will interpret the content
What Vector Alignment Can See:
- Semantic proximity between content and query in embedding space
- Conceptual coverage regardless of lexical overlap
- Intent alignment at a meaning level
- Semantic drift that keyword audits miss
What Vector Alignment Cannot See:
- Whether the measurement space matches the production retrieval system’s geometry
- How reranking layers will treat the result after initial retrieval
- Whether the LLM’s generation layer will interpret the content as authoritative
- Cross-model score equivalence (0.85 here ≠ 0.85 there)
The MTEB Benchmark: A Concrete Illustration of the Problem
The MTEB (Massive Text Embedding Benchmark) leaderboard tracks performance across current embedding models and makes the problem concrete.
The performance spread across models is not small. A content asset that scores well against one model’s embedding space may score materially differently against another — not because the content changed, but because the geometry of the measurement space changed.
The embedding model your scoring tool uses is almost certainly not the one any given AI platform uses in production. Google hasn’t published the specifics of its retrieval embedding layer. Neither has OpenAI, Anthropic, or Perplexity.
You’re measuring in a space that is representative of the general problem but not identical to the specific system where your content will actually be evaluated.
That’s not a reason to abandon measurement. It’s a reason to treat measurement with appropriate epistemic humility.
What Genuine Measurement Literacy Looks Like in Practice
The path forward isn’t choosing between keyword research and vector alignment. It’s building the literacy to use both correctly:
- Use keyword research to establish topical relevance at the lexical level. It remains a valid signal for what terms and phrases should appear.
- Use vector alignment scoring to identify semantic drift — cases where keyword coverage masks a mismatch between content framing and query intent.
- Treat alignment scores as directional signals, not verdicts. A 0.85 is more aligned than a 0.65. It is not proof that the content will perform well in any specific production system.
- Don’t optimize directly for the score. Optimize for the reader and the information need. The score should be a diagnostic tool, not an optimization target.
- Combine signals. A page that scores well on keyword coverage, shows strong alignment, has genuine depth, and generates user engagement signals is more likely to perform than a page tuned to maximize alignment score alone.
- Maintain the editorial judgment that high-resolution tools can make it tempting to skip. The best content strategists are doing something sophisticated when they read a piece and assess its intent alignment. That skill doesn’t become obsolete — it becomes more valuable when precision tools create false confidence for those who stop applying it.
For more related articles, visit The Brisk Digital.


No Comments